Regular Expression (Regex)
Have you ever wondered how to replace a pattern with another pattern in all files inside a directory?
The answer is very simple, using Regular Expressions.
This article helps you to quickly understand how a regular expression works and how to use them in particular situations. It will save you a lot of time and headache.
Regular Expression
A regular expression or regex, in computing is a sequence of characters that define a search pattern. They provide a concise and flexible means for identifying characters, words or patterns of characters in a text. If you are a programmer or not, regular expressions can help you in many situations such as:
*Validating data conform a desired format. (email , phone number ,etc.)
*To search and extract information from large documents.
* To replace particular items.
*To reformat text.
*Virus scanning.
* To search for patterns in genetic code in the field of bioinformatics.
You may find it hard at first, when trying to understand and use regular expression, it seems like a new language. However, using regexes can save you hours of work.
In regular expressions, there are two types of characters: literals and metacharacters.
A literal is a character that stands for itself. It matches the first occurrence of that character in the string, for example if the character is “A” it will match any character that is a capital ‘A’.
Metacharacters are characters that have a special meaning, they tell the regular expression how to match the other characters in the regular expression.
The most common types of metacharacters are:
- CHARACTERS ESCAPES
The backslash character ‘\’ in a regular expression indicates that the following character is special or literal.
| Character | Description |
| \b | Matches a backspace |
| \t | Matches a tab |
| \n | Matches a new line |
| \e | Matches an escape |
- CHARACTER CLASSES
A character class matches any one of the group of characters.
| Character | Description |
| [character_group] | Matches any of character group. |
| [^character_group] | Matches any of character, that is not of character group |
| [first character-last character] | Matches any of character, that is not of character group |
| . | Matches any single character except \n |
| \w | Matches any word character |
| \W | Matches any single character that in not a word character. |
| \s | Matches a white-space |
| \S | Matches any single character that is not a white-space |
| \d | Matches any decimal digit |
| \D | Matches any character that is not a digit |
- ANCHORS
Anchors are characters that cause a match to succeed or fail depending on the position of the characters in the string.
| Character | Description |
| ^ | The match must start at the beginning of the string |
| $ | The match must occur at the end of the string |
| \b | The match must occur between two boundaries |
- QUANTIFIERS
A quantifier specifies how many instances of the previous element (literal, group or character class) must be present in the string for a match to occur.
| Quantifier | Description |
| * | 0 or more times |
| + | 1 or more times |
| ? | 0 or 1 time |
| {n} | Exactly n times |
| {n ,} | At least n time |
Example 1: Email validation
Regex: ^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$
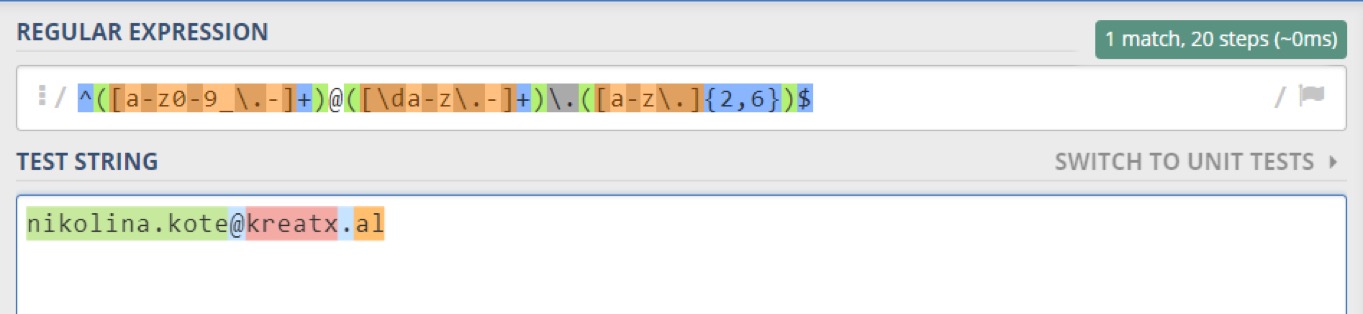

Description:
We begin by telling the parser to find the start of the string, followed by the first group of characters that matches with any character between letter a and z, any digit from 0 to 9, underscores, escape character and dot. The escape character before the dot means that dot should be interpreted literally. After that, there must be ‘@’ sign. At sign is followed by the second group of characters which represent the domain name. This group contains one or more digits, letters from a to z, underscores or dots. Then there is another escaped dot, with the extension that must contains 2 to 6 letters or dots. Finally, we end with the $, which represents the end of the string.
Example 2: Albanian telephone number validation

Description: ^ asserts position at start of the string. The number starts with or ‘+’, followed by the prefix for international calls 355. Number may be formatted separated or not, by a white space, a hyphen or a dot. Next comes the area code within Albania, which contains from 1 to 3 digits. Area code is followed by 6 digits separated or not between every group of thousands. Finally, in this example the $ tells the regular expression to match anything at the end of the string.
Strings that matches: +35542123123, 0355-42-123-123, +355 852123123
How to use regular expression in Notepad++
To finally solve the problem mentioned at the beginning, let’s see how we can use regular expressions in Notepad++ text editor.
- At first, press CTRL+H in order to display the Find and Replace Modal.
- Choose Regular expression as search mode.
- In the find what field we will use the expression for the search pattern, and in replace with field we will put the expression for replacement.
- In the Directory we will define the path of the directory containing the files we what to apply the replacement.
- Finally, press Replace in Files.
Replace in files allows both finding and replacing. You can choose any extension filter and the containing folder.
In this case we want to replace :
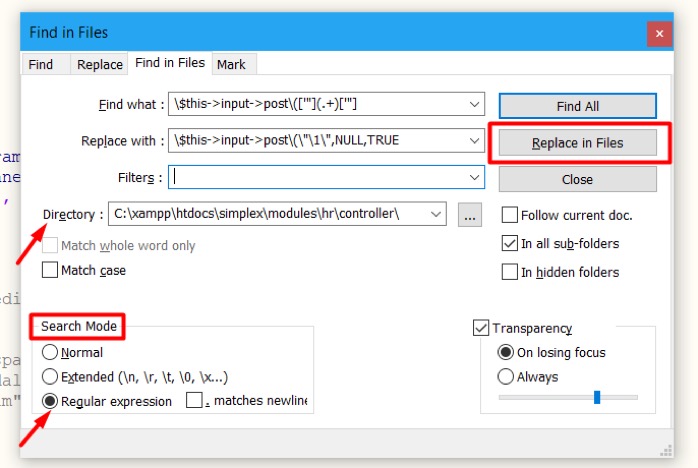
$this->input->post(“parameter_name”);
With $this->input->post(“parameter_name”,NULL,TRUE);
Since the parameter name is different, there is the need for using regular expressions to make the replacement.
To do so, regexes supports tagged expressions. This is accomplished using () to surround the text you want to tag, and then using \1 in the replace pattern to substitute the first matched text, \2 for the second etc.
In 1997, Jamie Zawinski famously wrote:
In a difficult situation, some people think “I know, I’ll use regular expressions.” Now they have two problems.” It’s just a joke, don’t be afraid using regexes, they will make your life a lot easier. I hope you will be using them in your future projects.

References:
https://en.wikipedia.org/wiki/Regular_expression
http://docs.notepad-plus-plus.org/index.php/Regular_Expressions